
1. RAID(Redundant Array of Independent Disks)
- 여러 개의 데이터 조각으로 배열된 각각의 디스크를 의미한다.
- 배열이란 한 데이터를 쪼개서 각 디스크에 저장하는 것을 의미하며, 크게 스트라이핑(striping) 과 미러링(mirroring) 으로 나뉜다.
- 단일 저장장치의 용량이 수TB로 커지게 되면서 RAID의 실용성에 의문이 제기되고 있다.
- 거대한 용량을 다루게 되면서 디스크 복구 작업이 길어지고
- 한두 개의 디스크 오류에 대처 가능한 정도로는 부족하기 때문
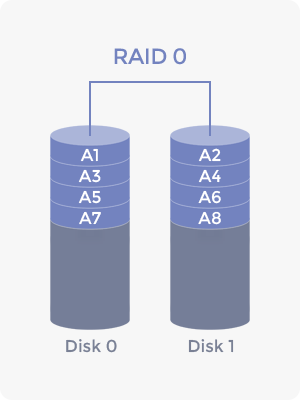
스트라이핑
- 데이터를 병렬로 분리하여 저장하는 방식
- 데이터를 각 디스크에 저장된 조각들을 동시에 불러와서 모은다.
- 속도가 빠르고 디스크별 부하를 줄일 수 있다.
- 디스크가 하나라도 망가지면 데이터 조각이 유실되어 데이터 무결성에 문제가 발생한다.
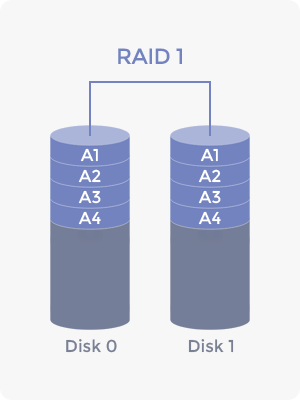
미러링
- 같은 데이터를 복수의 디스크로 동시에 저장하는 방식
- 디스크 하나가 망가져도 다른 디스크에 같은 데이터가 존재하기 때문에 데이터를 보존할 수 있다.
- 미러링 된 만큼 추가 공간을 차지하기 때문에 공간 효율 측면에서 좋지 않다.
패리티(Parity)
- 데이터를 복구하기 위한 수단
- 원본 데이터에 특정 알고리즘을 이용해 생성한 추가 데이터
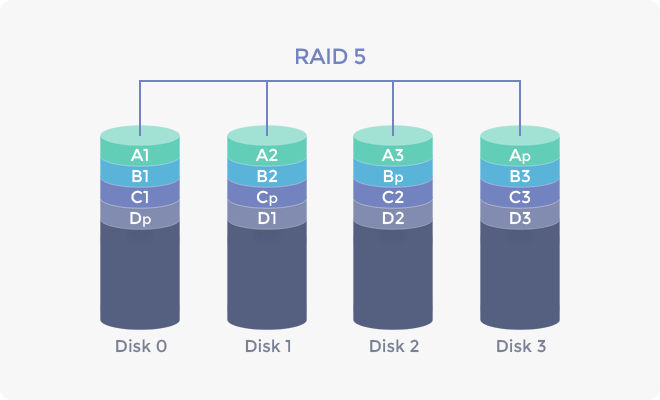
RAID 5
- RAID 5 구성의 경우 데이터별 패리티를 1개씩 생성하며 XOR 비트 연산을 이용한다.
- N-1개의 디스크에 데이터를 스프라이팅 방식으로 저장하고 XOR 연산으로 계산해 패리티를 생성한다.
- 한 개의 디스크가 고장나면 나머지 디스크를 XOR 연산하여 데이터를 복구할 수 있다.
- 2개 이상의 디스크가 고장나면 1개의 패리티로는 복구가 불가능하다.
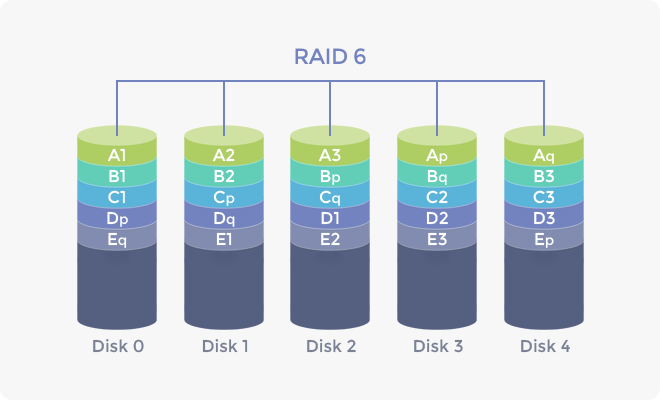
RAID 6
- RAID 5를 보완하기 위한 방식으로 2개의 패리티를 사용한다.
- XOR 대신 Reed-Solomon Code로 패리티를 생성한다.
- Reed-Solomon Code : 256 byte 블럭 내에 n byte 보정 정보를 포함시켜, 최대 n 개 오류를 검출하고 최대 n/2 개 오류를 복구할 수 있다.
- 라고는 하는데… (wiki)
2. 이레이저 코딩(Erasure Coding)
- RAID와 마찬가지로 데이터 손실 시 미리 준비된 별도의 데이터(패리티)로 복구하는 기술
- 원본 데이터를 n개의 데이터 조각으로 나누고 k개의 패리티를 생성.
- 최대 k개의 데이터가 손실 되어도 n개의 데이터만 살아 있으면 원본 데이터가 복구 가능한 방식이다.
사용되는 알고리즘
- Reed-Solomon Code
- Tahoe-LAFS
- Weaver code
동작방식
- 데이터 원본을 n개로 나눈다.
- n개의 데이터를 가지고 연산과정(인코딩)을 통해 k개의 패리티를 생성한다.
- 데이터 손실시, n개의 데이터로 디코딩을 통해 원본 데이터를 복구한다.

RAID와의 차이점
- 데이터 보호 수준을 유연하게 설정할 수 있다.
- 10조각짜리의 블록을 인코딩해서 추가로 6조각의 패리티를 생성하는 경우
- 16군데의 노드나 디스크에 분산 저장
- 복구시 필요한 조각 = 10조각
- 6개의 오류가 발생해도 원본 데이터를 복구할 수 있다.
- = RAID에 비해 더 많은 디스크 오류에 대처할 수 있다.
- 10조각짜리의 블록을 인코딩해서 추가로 6조각의 패리티를 생성하는 경우
단점
- 소프트웨어 RAID처럼 모든 작업이 소프트웨어로 처리되고 모든 데이터를 인코딩하는 만큼 패리티 계산에 CPU 오버헤드와 지연시간이 발생
- 블록 스토리지와 같이 작은 블록 입출력이 발생하는 스토리지 시스템은 블록별 계산이 많아지기 때문에 전반적인 스토리지 성능에 영향을 줄 수 있다.
3. 오브젝트 스토리지
- 비정형 데이터를 안정하게 저장하고 관리하기 위해 등장
- 오브젝트라 불리는 독립된 유닛에 데이터가 저장되고 관리되는 데이터 스토리지 아키텍처
- 각각의 오브젝트에는 키, 데이터, 옵션 메타데이터가 포함
- 데이터의 물리적인 위치는 상관 없이 사용자나 서버에서 식별할 수 있는 ID를 오브젝트에 부여하여 관리
- 플랫(flat)한 구조로 API 친화적이며, 확장성이 매우 높다.
- 폴더 계층 구조 없이 평면 구조로 저장된다.
- 백업, 아카이빙 비디오 파일, 가상머신 이미지 파일 등의 데이터를 저장하는데 적합
- 거대한 비정형 데이터를 여러 노드에 분산 저장할 수 있고 심플한 확장성 때문에 이레이저 코딩과의 활용이 용이
단점
- 하나의 파일을 업데이트 할 때마다 모든 복제본이 업데이트 될 때까지 기다려야 하기 때문에 데이터를 자주 바꿔야 하는 업무에는 권장하지 않음